Introduction
Lately, I decided to explore some other notable open source projects. Apache Kafka is a project I heard about years ago, but I never encountered work that warranted its use. After I shifted into the software development world and became more accustomed to working with large datasets, specifically through web scraping, Apache Kafka came across my radar once again. Apache Kafka, as defined by the Apache Foundation, is an open source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission critical applications. Apache Kafka has an extremely high throughput and can scale to large numbers. The core of Apache Kafka is written in Java and its famous Streams API is written in Java as well. I had a sinking feeling, at first, that to use Apache Kafka well, I would have to learn Java. Fortunately, I learned there are many open source Kafka clients/bindings written in other languages, like Python. For this project, I chose to use Confluent’s Kafka Python Client. One of my personal projects that I find really interesting to work on is a Google Flight price scraper. Even though some people see web scraping as dull, I find collecting data and making decisions quite interesting, especially when it revolves around travel. One of my favorite destinations to travel to is Japan. For this project, I chose to incorporate Apache Kafka components to my existing Google Flight scraper. In the end, I want to achieve basic streaming and use ksqlDB to interact with the flight data as its flowing in real time.
Use Case Diagram
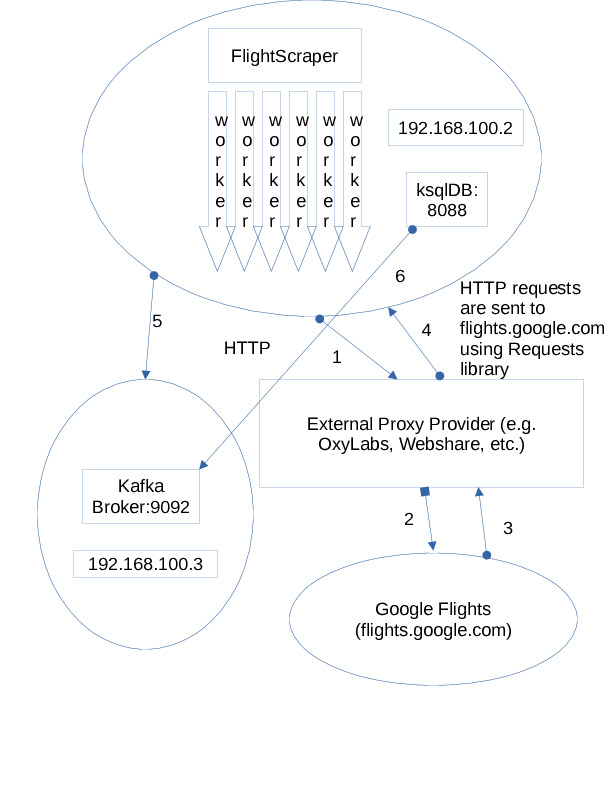
To help illustrate this use case, I created a basic diagram in LibreOffice Draw. I hope this diagram explains the use case in an easy way:
How It Works
The Google Flight price scraper is called FlightScraper. FlightScraper is written in Python and uses requests to fetch HTML content from flights.google.com. Once the HTML has been fetched, Beautiful Soup then parses out the flight information from the page. In order to prevent Google’s bot protections from interfering with the data collection, all HTTP requests will go through a rotating proxy endpoint via a third-party provider. Only one node will perform requests using a multithreaded approach. The request load being sent is small compared to other large botnets that may act maliciously. DISCLAIMER: Please act responsibly when scraping data from a website.
The processing is numbered in order by start to finish. That is, 1 signifies FlightScraper sending out the HTTP request to the external proxy endpoint. Once the proxy endpoint receives the request, the proxy then handles the completion of the request to flights.google.com. Once flights.google.com processes the request, the response is sent back to the proxy endpoint that originally established the request and from there, the proxy endpoint relays the response back to the threaded worker that started the whole process. FlightScraper will then parse the data using Beautiful Soup and then build a JSON object that represents the flight.
How Kafka Is Involved
Once the flight data JSON has been created, FlightScraper will then produce a message to the configured Kafka topic. In this case, the Kafka topic is called flight-data. The Kafka message is sent to the Kafka topic that exists on the broker. Like many distributed systems, Kafka can scale to hundreds or even thousands of brokers. Kafka will ensure messages in a topic are protected from data corruption in the best way it can. Kafka messages sent to a broker are also ordered, which ensures real-time applications built around Kafka don’t receive data that may be “old”. If data changes frequently, then even a message from a minute ago might be considered outdated. Finally, in order to leverage and manipulate the incoming data, ksqlDB is used. ksqlDB is a project that works with Apache Kafka to provide a SQL-like layer to Kafka data. If an user knows SQL-like functions, they can use that knowledge to interact with incoming data. In the following examples, ksqlDB will be used to filter out incoming flights that don’t match certain criteria.
FlightScraper in Action
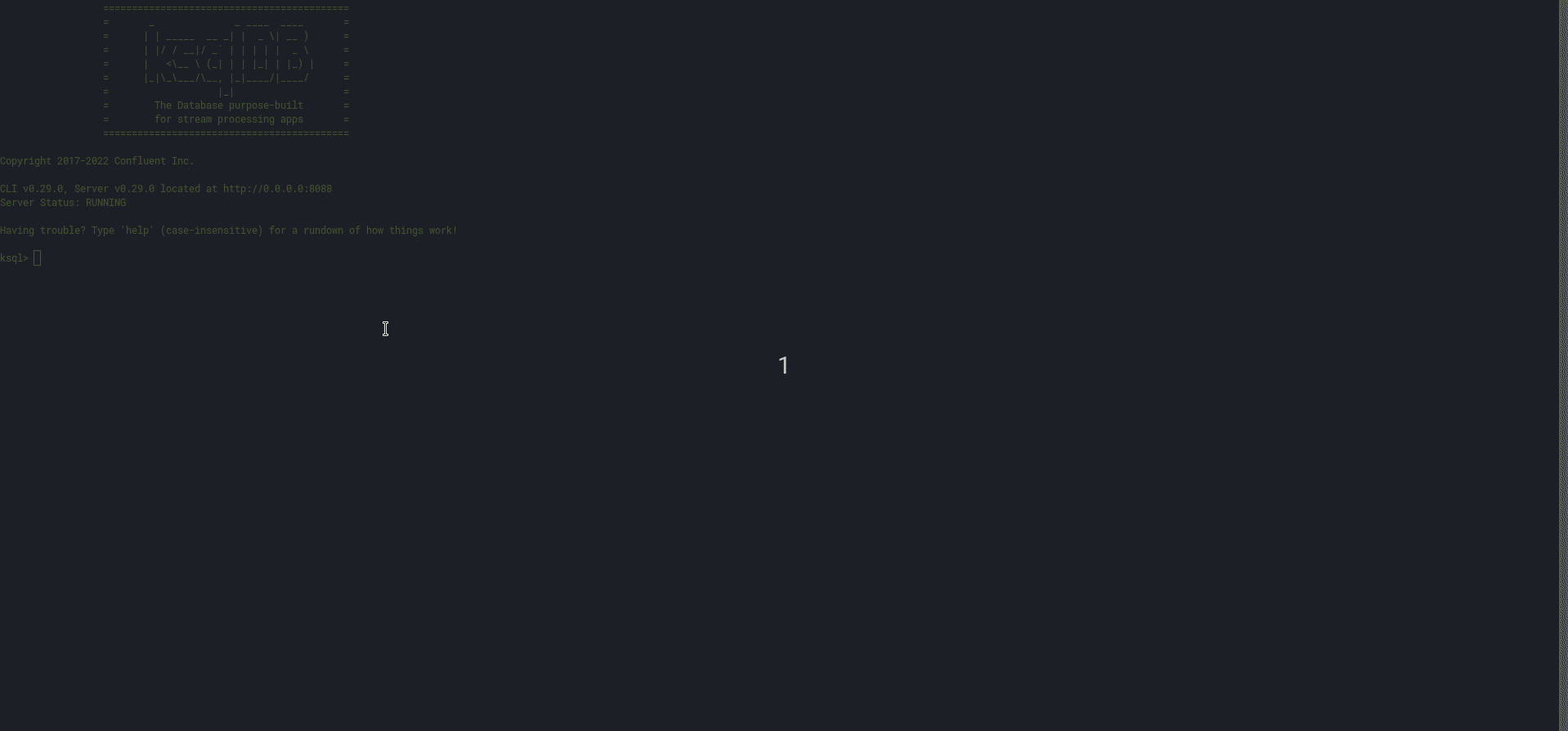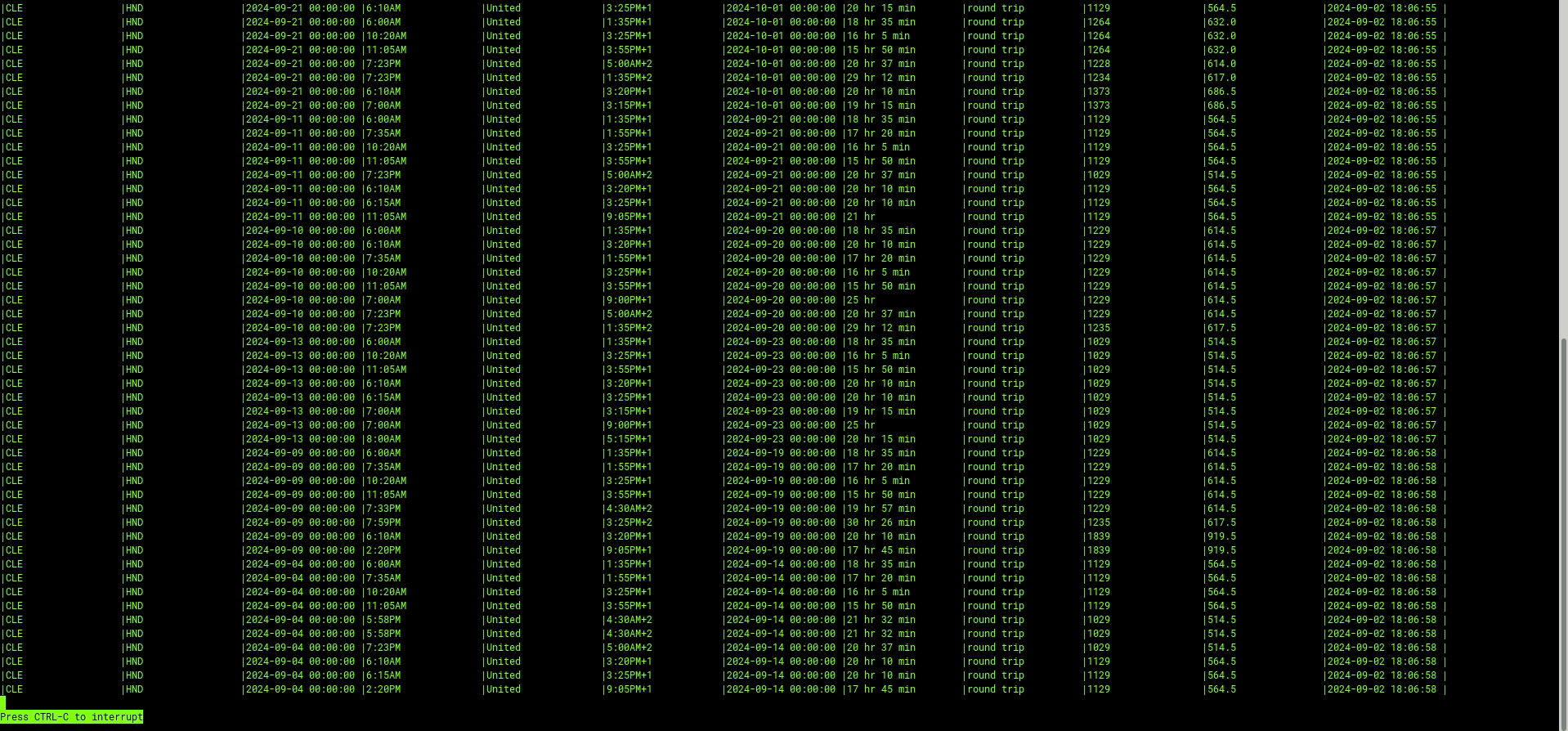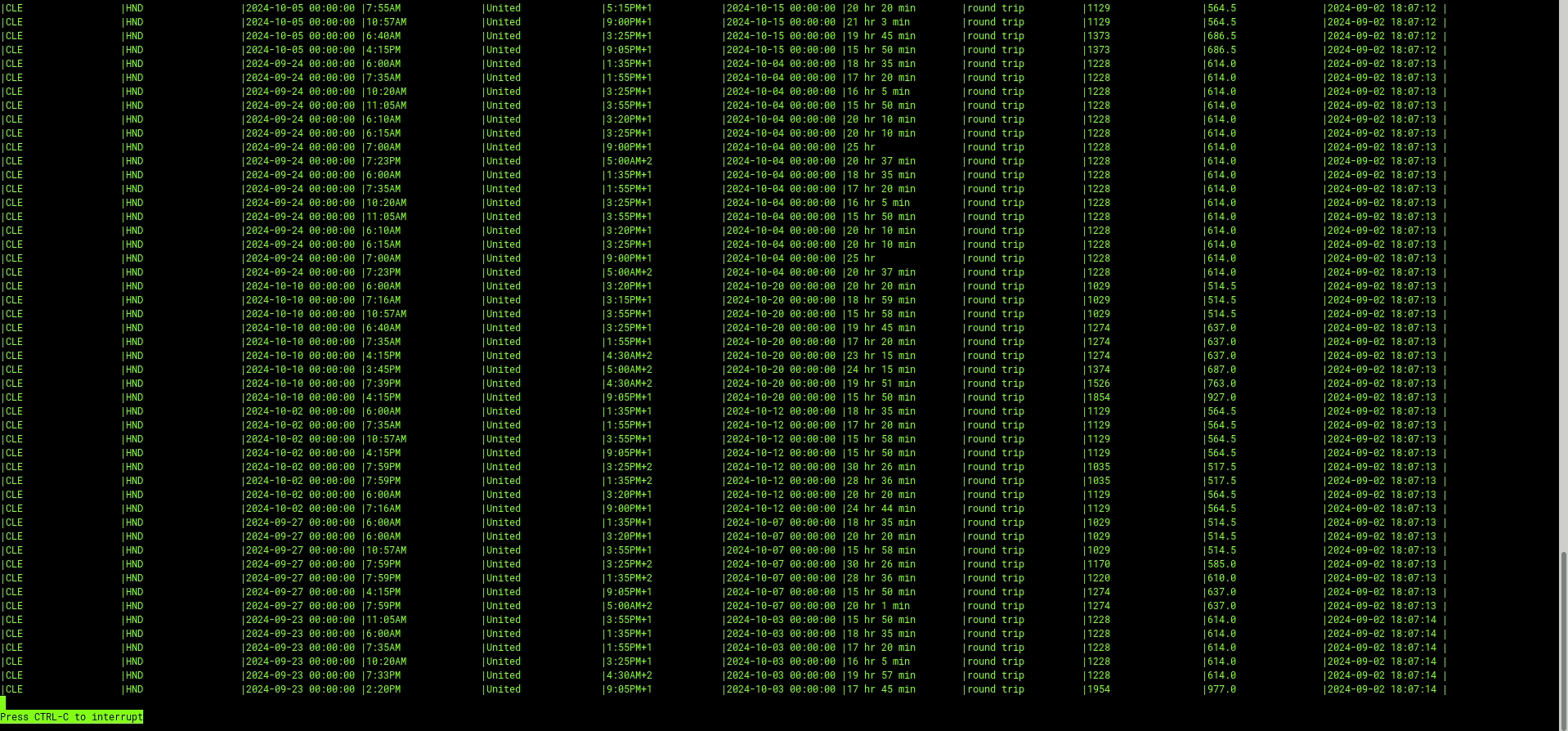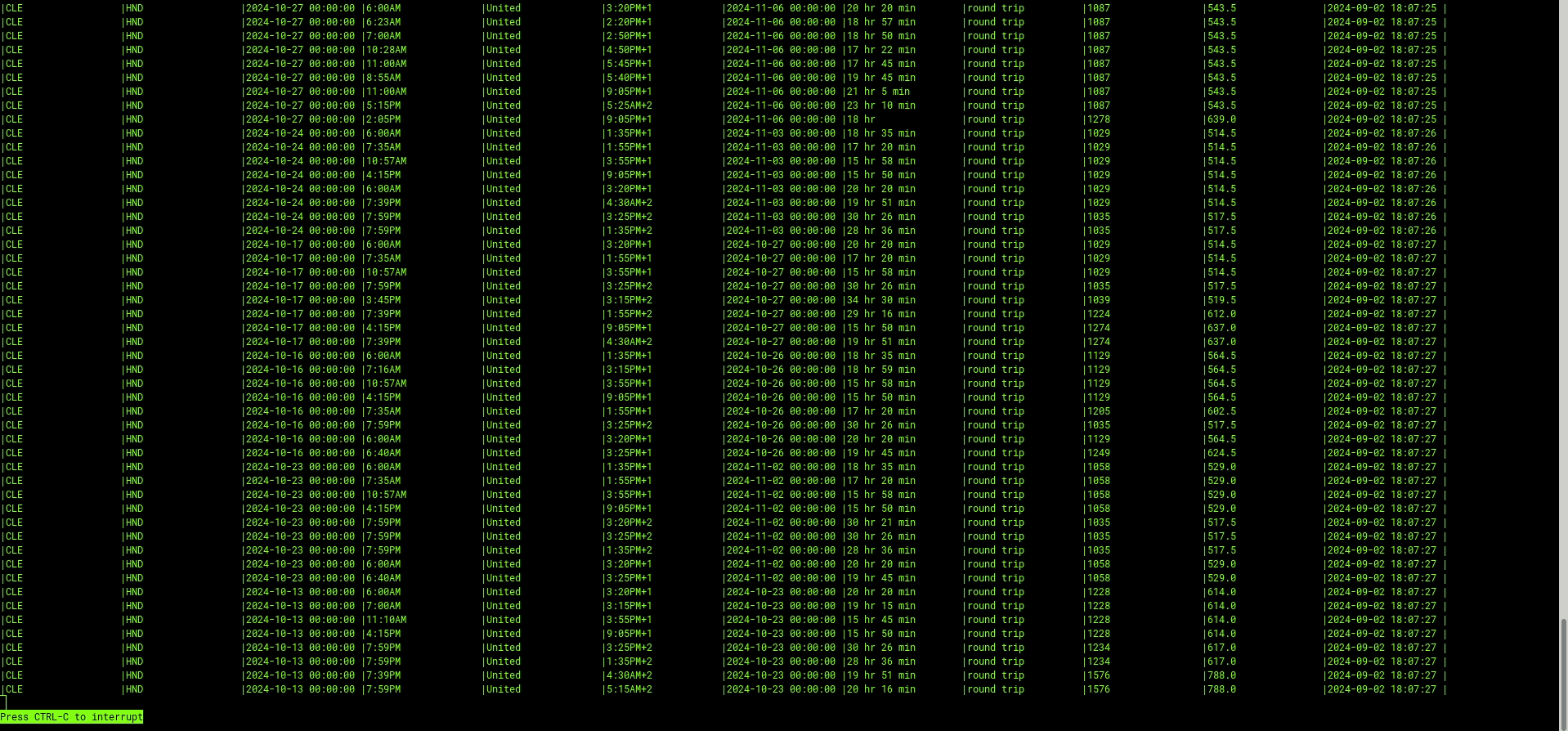
Now that FlightScraper’s architecture has been outlined, let’s actually start seeing the data it produces. FlightScraper has additional abilities, like being able to produce date ranges based on how long a trip will last. In the following examples, I will have FlightScraper generate 10-day date ranges for flights going from Cleveland (CLE) to Haneda (HND) from today (i.e. 9/2/24) into the future by 180 ranges (each range will have 10 days). As the data flows into the Kafka broker, ksqlDB will then process the data and EMIT the changes as they come in real time.
In order to interact with the Kafka data via ksqlDB, we’ll need to create a stream based on the Kafka topic. Here’s an example of a query that creates a stream based on incoming data to the Kafka broker:
CREATE STREAM flights (origin VARCHAR, destination VARCHAR, embarkDate TIMESTAMP, embarkTime TIMESTAMP, airline VARCHAR, arrivalTime TIMESTAMP, departDate TIMESTAMP, duration VARCHAR, flightType VARCHAR, price INTEGER, pricePerWay DOUBLE, timestamp TIMESTAMP) WITH (kafka_topic='flight-data', value_format='json', partitions=3);
Before creating the preceding stream, we need to spin up ksqlDB. You can start ksqlDB by running the following command:
sudo /usr/bin/ksql-server-start /etc/ksqldb/ksql-server.properties
/usr/bin/ksql http://0.0.0.0:8088
Now, for the grand finale, let’s see how the data gets represented:
(Example Using Just a Simple SELECT *)
As I mentioned before, ksqlDB allows users to leverage SQL-like functionality to manipulate and change how the data stream is represented. In the next example, I’m going to filter the price and only return flights that are less than or equal to $1,050:
(Example Using a <= Comparison)

The preceding examples are just basic use cases of Apache Kafka and ksqlDB. From my experiences with this project, I can now think of many different use cases where streaming data can be built into real-time applications. Apache Kafka and ksqlDB make a great pair for building dynamic and real-time platforms. If you haven’t checked out Apache Kafka or ksqlDB, you should!
Credits:
Apache Kafka in 100 Seconds – https://www.youtube.com/watch?v=uvb00oaa3k8
ksqlDB SQL Quick Reference – https://docs.ksqldb.io/en/latest/developer-guide/ksqldb-reference/quick-reference/
apache/kafka – https://hub.docker.com/r/apache/kafka
ksqlDB Quick Start – https://ksqldb.io/quickstart.html